
在pytorch安装时踩到了不少坑,看了好多博客,最后整合了一份不会踩坑的安装教程,主要是参考各个博主的内容,从零开始安装pytorch,分享给大家!
因为这篇文章是整合各个链接,所以我自己可能写的比较简略,只是为大家提供一个流程,解释的不明白的就点进各位大佬的博客详细看就可以了。
最重要的是:这些链接我会提示你只看指定的位置,不是全部,不是全部,不是全部!
首先在安装pytorch之前,先要安装CUDA,因为一般我们都是用GPU去跑深度学习程序。
cuda安装参考链接:https://blog.csdn.net/Mind_programmonkey/article/details/99688839
安装CUDA时,先看电脑上有没有独立的NVDIA显卡,在设备管理器中查看,如果显卡支持,接下来到回到桌面,右键-NVDIA控制面板-帮助-系统信息,你会看到下图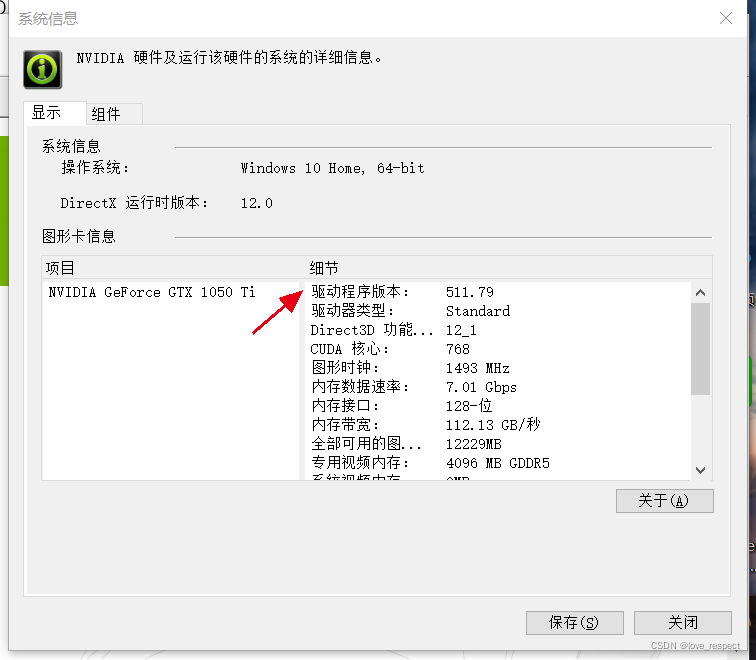
红色的箭头就是显卡驱动程序版本号,接下来点击组件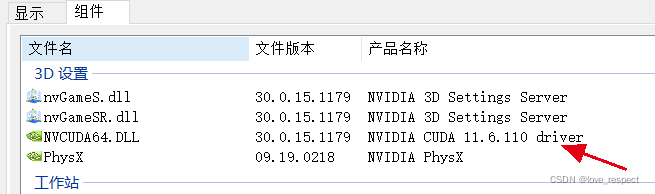
这个也就是你最高支持的CUDA版本,目前我这里是11.6,但是我建议大家不需要装最新的,因为目前不容易找到11.6的配套内容,如torch版本等,我有些同学在win11的系统上下载的11.6版本的CUDA,后来发现其他资源不好找,索性又重新换,来回很麻烦,所以我建议还是装前几个版本就够用,下面我用11.3举例
CUDA下载链接:CUDA Toolkit Archive | NVIDIA Developer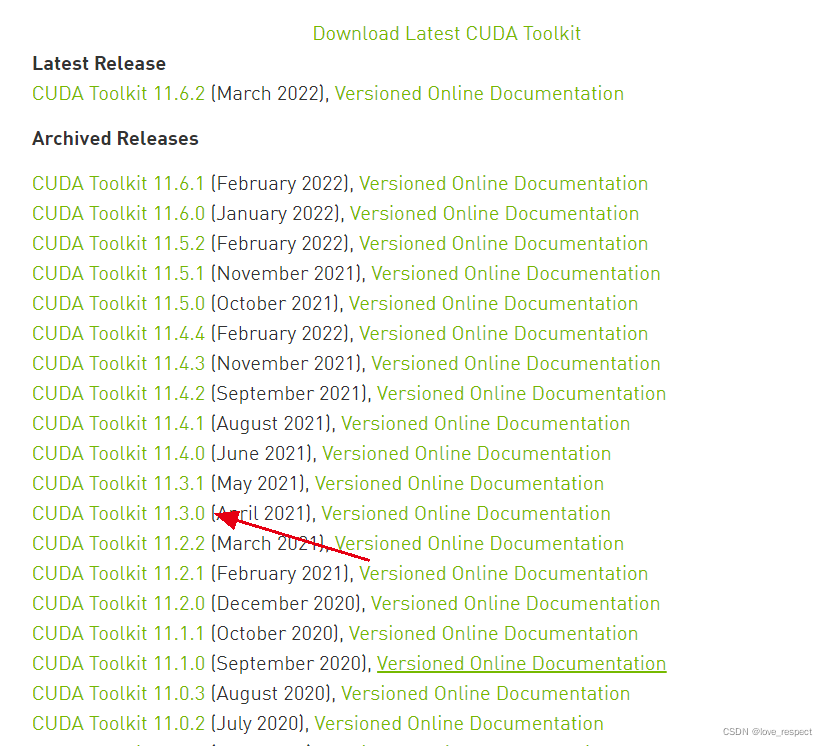
点开后点11.3这里,如果下载其他版本的,也是直接点版本就可以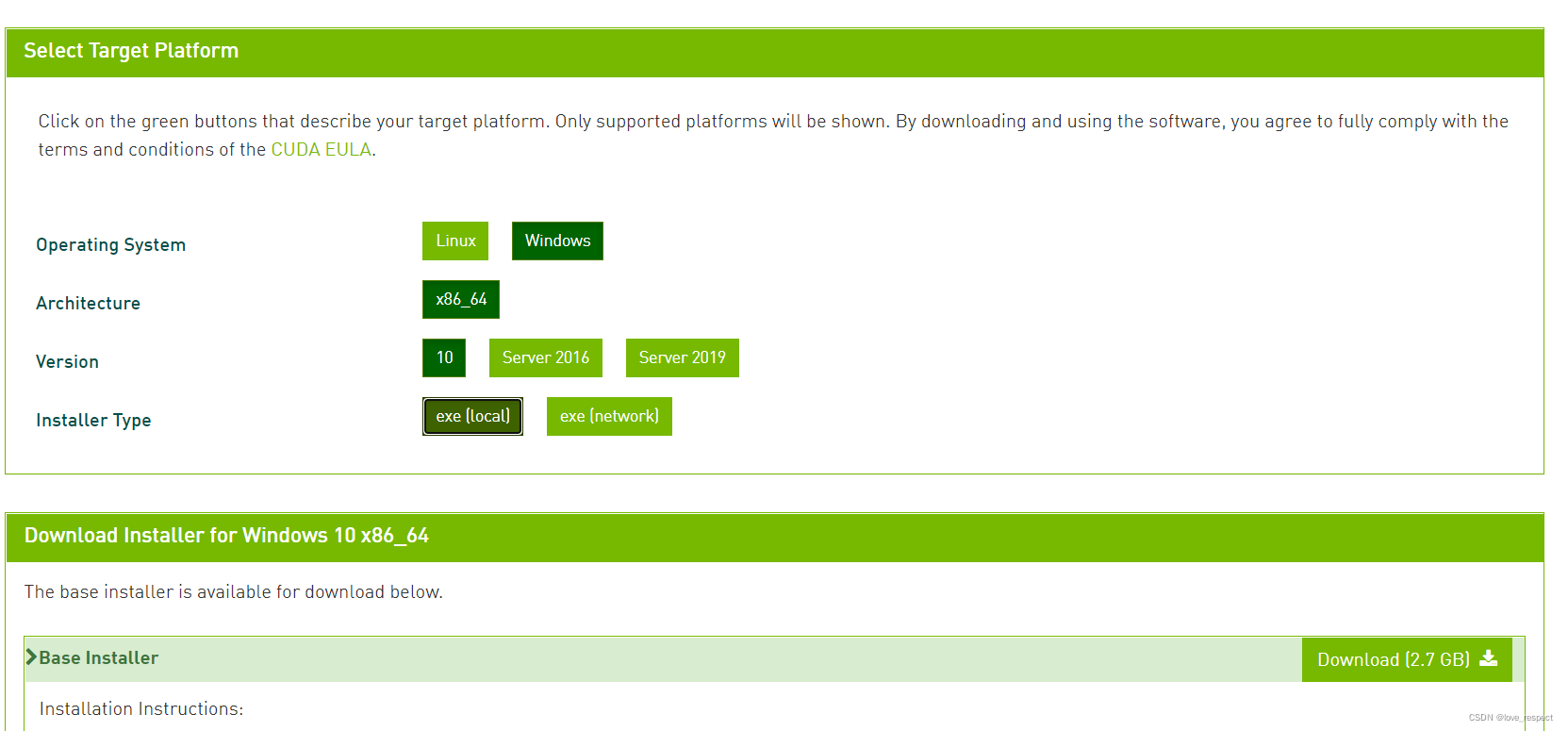
跳转页面如上图选择就可以了,选择后点击下载,下载好后点安装,安装过程大家可以参考我上边分享的CUDA安装的博客,非常详细,安装完以后,接下来就是配置环境变量了,我配置环境变量并没有使用这个up主的方法,而是用的下面这一篇,更详细一些
CUDA环境变量配置
win10下CUDA和CUDNN的安装(超详细)!亲测有效!_没有人喜欢一个人的博客-CSDN博客_cuda安装
下面附上我的环境变量配置
因为我安装了两个版本的CUDA,所以多了一行,大家按11.1样式就可以,这里咱们用11.3举例是一样的,主要是去文件结构下把这些原封不动的粘贴到变量值就可以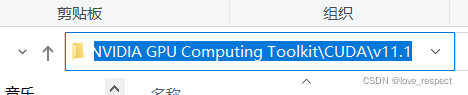
然后PATH变量是这样的
我这里太乱了,大家看上文博主规范的就好
注意这个博主箭头这里的目录结构应该和大家不一致,这是他自己创建的文件结构,我建议第一次安装的同学默认c盘,不太能出错
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v11.1
我的路径大概是差不多这样的结构,只要你是默认安装,应该就是这样的,注意一个是Program Files,另一个是ProgramData
到此,cuda就安装好了,记得用博客中的命令行验证安装是否正确,接下来,要安装一个cudnn,参考这个链接,和上文那个是同一篇
win10下pytorch-gpu安装以及CUDA详细安装过程_mind_programmonkey的博客-CSDN博客_pytorch-gpu安装
cudnn下载链接
cuDNN Archive | NVIDIA Developer
点开之后是这样的
我们点击箭头这个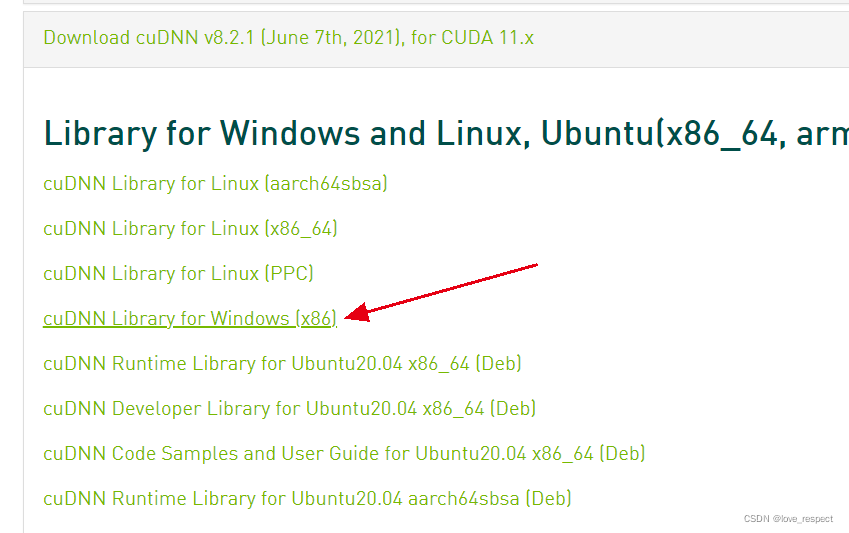
安装windows就可以,安装cudnn需要一个NVDIA账号,按照流程注册一个就好,需要用到邮箱
下载之后,解压缩,将压缩包里面的bin、clude、lib文件直接复制到CUDA的安装目录下,直接覆盖安装。
就是这几个放到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1这个目录下,你自己的和我的可能版本号不一样,按你自己的文件结构来就行,覆盖安装
好的,CUDA和cudnn这里就告一段落
然后我们需要下载anaconda,这是一个管理python环境的东西,有了这个,干啥都很方便,这个还是安装非常简单的,我附上一个b站的视频链接吧,跟着大佬一步步做就可以了
Anaconda和pycharm安装教程
【python编程环境安装】全网最详细python环境安装。pycharm和anaconda手把手安装教学。_哔哩哔哩_bilibili
pycharm是一个python编程软件,应该大家都会用到
装好anaconda后,我们来到开始界面,找到这个
点开以后就是命令行,现在我们要建一个Python的虚拟环境来安装pytorch,输入
conda create -n PyTorch python=3.9
这个就是创建环境的语句,这个PyTorch只是一个环境名,自己起就行,建议不要太繁琐,我自己的就叫做kpytorch,然后python版本这里都可以3.8,3.9没什么限制,创建好环境以后,输入activate kpytorch(这个kpytorch就是你的环境名)就到了你的虚拟环境中了,这时输入python就能显示python版本号,进入python编程模式,如果要退出,输入exit()就可以。
接下来一般的安装教程都会让大家去找pytorch的官网,利用网址和镜像源去安装,但是我身边的同学们用这种方式出现了各种各样的错误,所以我建议大家用离线安装:
首先从这个链接下载torch和torchvision
下载链接:https://download.pytorch.org/whl/torch_stable.html
下面这个链接是torch和torchvision的对应关系查询,我下边也附了一张常用图,你的这两个东西的版本和python版本,cuda版本都必须对应好
https://github.com/pytorch/vision#installation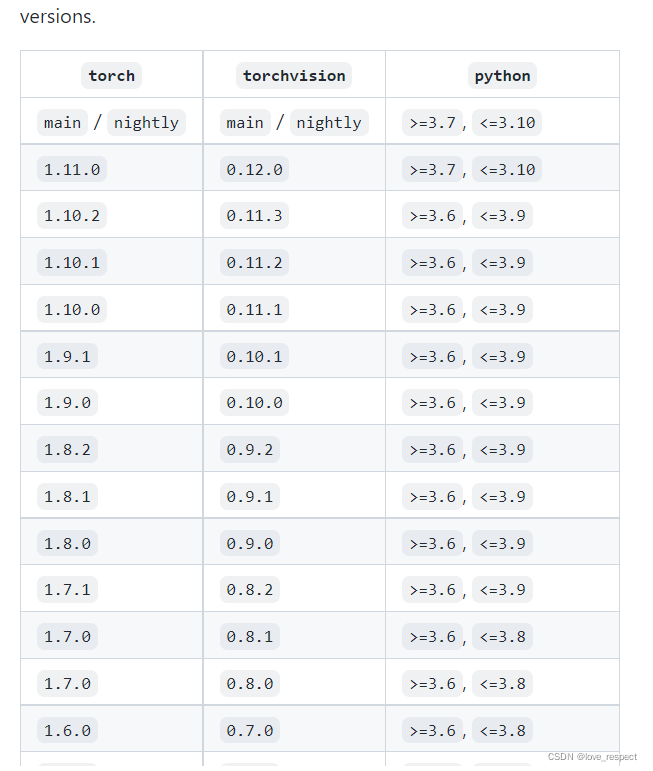
点开下载链接是这样的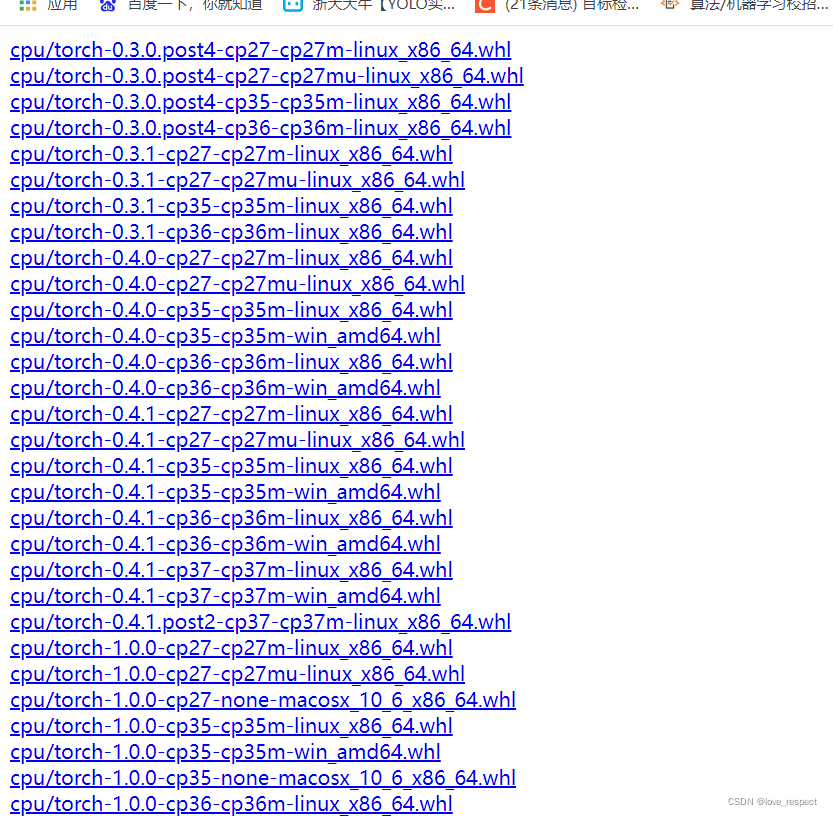
往下找,按照cuda11.3举例和python3.9举例,你需要找到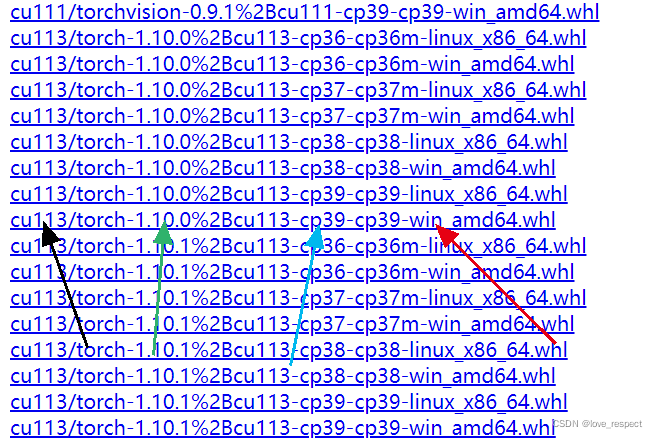
这几个都要对应好,cu113就是cuda11.3,绿色箭头是torch版本,蓝色39就是python版本3.9,然后都有linux和windows两种,选择Windows版本,根据你自己的各个版本去下载对应的whl文件
然后按照torch和torchvision那张图去找你对应的python版本,比如torch1.10.0对应的torchvision版本就是0.11.1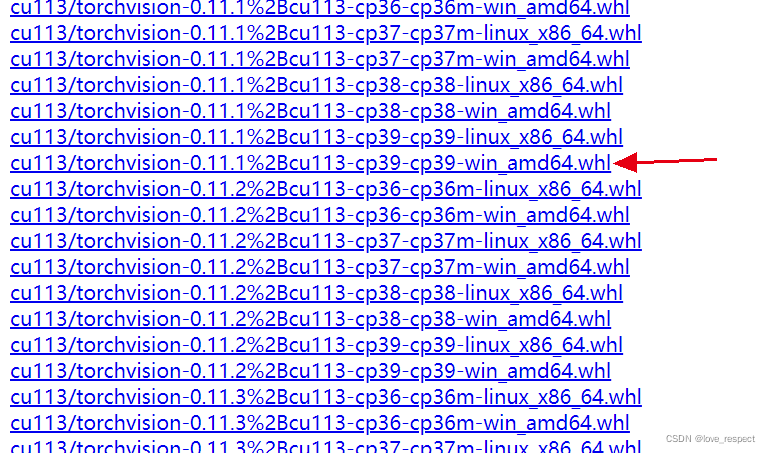
按照上边对应的方法,选择这个就是正确的,下载好两个whl文件后,用anaconda Prompt切换到你的虚拟环境,就是上文那个命令行,在你的虚拟环境中切换到你两个whl文件的安装目录,用cd切换应该都会吧,重点来了:anaconda是不能整体路径切换的,必须要一层一层切换,具体解释看下面这个链接
Anaconda切换盘符不成功:https://blog.csdn.net/c20081052/article/details/88839479
还是用我的举例,注意细看我切路径的方式,我的whl文件就放在D盘的搜狗高速下载中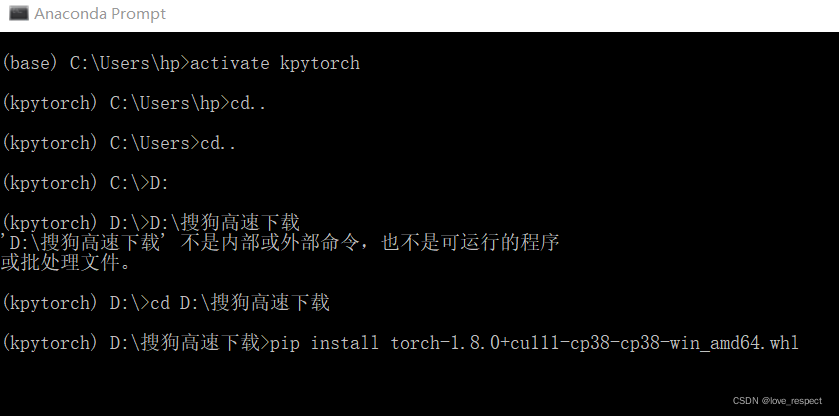
然后最后一句,在文件名前加pip install去安装这两个文件,都安装完后,就大功告成了
最后验证一下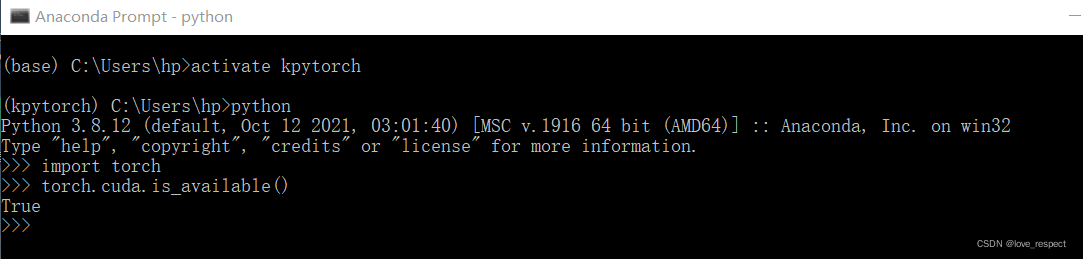

这样就OK了
第一次写博客,不知道是否有遗漏的内容,如果大家中途卡在某一步,可以在下方评论
————————————————
版权声明:本文为CSDN博主「孔德浩」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/love_respect/article/details/124681233
IBM Cloud CLI环境可以同时Access IBM云平台的IaaS,PaaS以及SaaS服务,而SL CLI仅访问IBM云平台的IaaS(基础硬件)环境。
第一部分:运行环境的准备
一、设置IBM Cloud CLI运行环境:
1.)运行安装命令
1.对于 Mac 和 Linux™,请运行以下命令:
#curl -sL https://ibm.biz/idt-installer | bash
1.对于 Windows™ 10 专业版,请以管理员身份运行以下命令:
[Net.ServicePointManager]::SecurityProtocol = "Tls12"; iex(New-Object Net.WebClient).DownloadString('https://ibm.biz/idt-win-installer')
2.)验证安装
ibmcloud help
3.)配置环境
使用 IBM 标识登录到 IBM Cloud。如果您有多个帐户,系统会提示您选择要使用的帐户。如果未使用 -r 标志指定区域,那么还必须选择区域。
ibmcloud login
4.)使用插件扩展 IBM Cloud CLI (可选)
IBM Cloud™ CLI 支持通过插件框架来扩展其功能。您可以从存储库或 Web URL 安装插件,也可以在本地安装插件二进制文件。
从 IBM Cloud CLI 存储库安装插件
搜索插件
使用 ibmcloud plugin repo-plugins -r REPO_NAME 命令在存储库中查找插件。
IBM Cloud CLI 提供名称为“IBM Cloud”的正式插件存储库,您可以进行搜索,如以下示例所示:
ibmcloud plugin repo-plugins -r "IBM Cloud"
几种安装插件的方式:
1.常用方式安装插件
使用 ibmcloud plugin install PLUGIN_NAME -r REPO_NAME 命令安装插件。例如,使用以下命令安装官方 IBM 插件存储库“IBM Cloud”中的插件:
ibmcloud plugin install auto-scaling
2.在本地安装插件
使用 ibmcloud plugin install LOCAL_FILE_NAME 命令在本地计算机上安装插件二进制文件。例如:
ibmcloud plugin install ./auto-scaling-darwin-amd64-0.2.7
3. 通过 Web URL 安装插件
使用 ibmcloud plugin install URL 命令直接通过 Web URL 安装插件。例如:
ibmcloud plugin install https://plugins.cloud.ibm.com/downloads/bluemix-plugins/auto-scaling/0.2.7/auto-scaling-darwin-amd64-0.2.7
二、设置SL CLI运行环境
1.) Linux环境安装SLCLI环境,确保linux系统已经安装有python环境,并且已安装有pip运行程序。然后运行以下命令安装SLCLI环境:
#pip install softlayer
2.) Windows环境下安装SLCLI运行环境, 安装python环境和pip运行程序,然后在windows命令行窗口执行:
C:\Users\xxx>pip install softlayer
第二部分:设置命令行运行环境的用户认证
设置用户和API Key:
一、IBM Cloud CLI设置用户登录
登录到IBM Cloud CLI:
ibmcloud login [-a API_ENDPOINT] [--sso] [-u USERNAME] [-p PASSWORD] [--apikey KEY | @KEY_FILE] [--no-iam] [-c ACCOUNT_ID | --no-account] [-g RESOURCE_GROUP] [-r REGION | --no-region] [-o ORG] [-s SPACE]
命令选项说明:
-a API_ENDPOINT
API 端点,例如 cloud.ibm.com。
--apikey API_KEY 或 @API_KEY_FILE_PATH
API 密钥内容或用 @ 符号指示的 API 密钥文件的路径。
-u USER_NAME
用户名。可选。
-p PASS_WORD
用户密码。可选。
-c ACCOUNT_ID
目标帐户的标识。此选项与 --no account 选项互斥。
--no-account
强制在没有帐户的情况下登录。建议不要使用此选项,此选项与 -c 选项互斥。
-g RESOURCE_GROUP
目标资源组的名称。可选。
-r REGION
目标区域的名称,例如,us-south 或 eu-gb。
--no-region
强制在不设置目标区域的情况下登录。
-o ORG
目标组织的名称。不推荐使用该选项。请改为使用 ibmcloud target -o org_name。可选。
-s SPACE
目标空间的名称。不推荐使用该选项。请改为使用 ibmcloud target -s space_name。可选。
--no-iam
强制向登录服务器(而不是公共 IAM)进行认证。
--skip-ssl-validation
绕过 HTTP 请求的 SSL 验证。不建议使用此选项。
示例,
以交互方式登录:
ibmcloud login
使用一次性密码登录,并设置目标帐户、组织和空间:
ibmcloud login --sso -c MyAccountID -o MyOrg -s MySpace
使用具有关联帐户的 API 密钥:
ibmcloud login --apikey api-key-string -o MyOrg -s MySpace
使用没有关联帐户的 API 密钥:
ibmcloud login --apikey api-key-string -c MyAccountID -o MyOrg -s MySpace
使用一次性密码:(个人推荐)
ibmcloud login -u UserID --sso
然后,CLI 会提供一个 URL 链接并要求输入密码(IBMid密码):
One Time Code (Get one at https://URL_Link_To_Obtain_Passcode):
在浏览器中打开链接,以获取密码。在控制台中输入密码进行登录。
使用你的IBMid登录,然后获取一次性密码,如下图: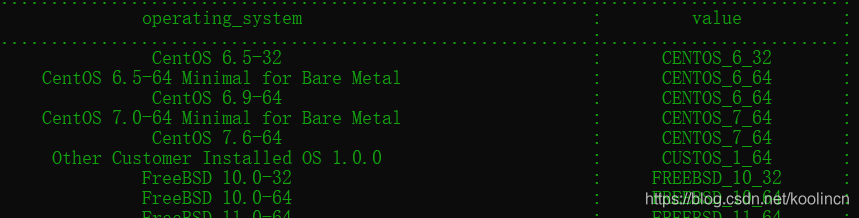
登陆后显示如下:
二、SLCLI设置用户授权Key
1.) 登录cloud.ibm.com网页,选择并点击管理—访问权(IAM)
2.) 点击左边菜单栏“IBM Cloud API密钥”
3.) 查看经典基础架构API密钥的详情,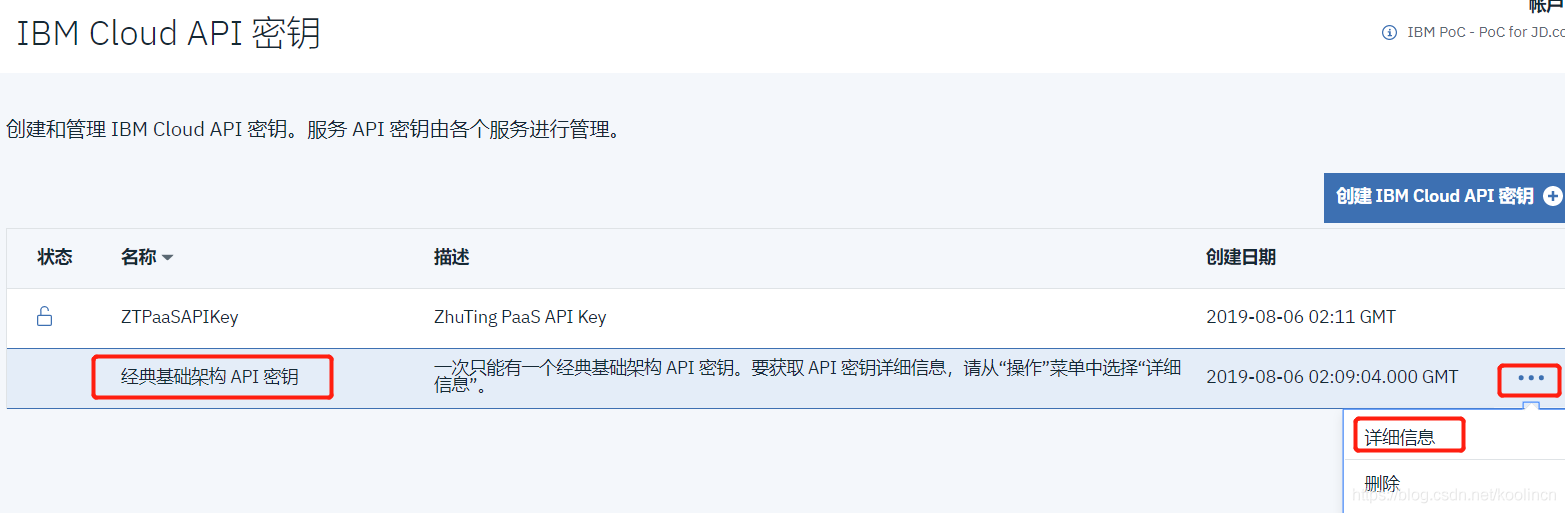
如果没有发现“经典基础架构API密码”条目,则说明还没有创建,可以点击右上角的“创建经典基础架构API”来创建,一个IBM Cloud账号只有一个经典基础架构API密钥。
4.) 记下用户名和API Key,如下图所示:
5.) 打开SLCLI命令行窗口,输入命令:
C:\Users\TINGZHU>slcli config setup
根据提示输入 “用户名”和“API Key”。
Endpoint项输入默认值:“回车即可”
Timeout使用默认值【0】:“回车即可” –永远不超时。
然后保存配置文件即可。
第三部分:使用命令行执行IaaS相关操作
使用SLCLI / IBM Cloud CLI for IaaS
常规经典基础架构服务命令:
使用 IBM Cloud CLI 中的经典基础架构命令可配置和管理基础架构服务。
运行 ibmcloud sl 命令
使用SLCLI,运行 slcli命令, 可查看可用命令的列表,
用法:
ibmcloud sl command [arguments...] [options...]
或 slcli command [arguments…] [options…]
command:
block 经典基础架构块存储器
file 经典基础架构文件存储器
dns 经典基础架构域名系统
globalip 经典基础架构全局 IP 地址
hardware 经典基础架构硬件服务器
image 经典基础架构计算映像
ipsec 经典基础架构 IPSEC VPN
loadbal 经典基础架构负载均衡器
security 经典基础架构 SSH 密钥和 SSL 证书
securitygroup 经典基础架构网络安全组
subnet 经典基础架构网络子网
ticket 经典基础架构管理凭单
vlan 经典基础架构网络 VLAN
vs 经典基础架构虚拟服务器
order 经典基础架构订单
user 经典基础架构管理用户
call-api 调用任意 API 端点
help 显示命令用法消息
要查看有关命令的帮助信息,请运行以下命令:
ibmcloud sl [command] -h
或者 sl [command] -h
使用样例:
1.查看账号下的硬件设备(物理机)
slcli hardware list
可以使用linux的shell命令进行更复杂的查寻,如搜索指定ip地址的物理机器,然后将之详细信息写入指定文件,以备后续使用:
slcli hardware list|grep “xxx.xxx.xxx.xxx”|awk ‘{print $1}’|xargs slcli hardware detail >> /home/myservers.log
2.批量将给定列表内所有的物理机将进行退库处理,表格中包含内网我ip地址和机器名:
3.将账号下的所有物理机器信息导入临时文件,文件包含“机器ID”,“机器名”,“公网ip地址”,“内网ip地址”,和“数据中心”信息
slcli hardware list > /home/temp-hw-list.log
4.将指定需要退库的ip信息保存到文件: /home/temp-ips.log
5.根据ip地址匹配出对应的机器ID信息并保存:
cat /home/temp-ips.log|while read LINE; do cat /home/temp-hw-list.log|grep “$LINE “|awk ‘{print $1}’ >> /home/temp-ids.log; done
6.读取机器ID,并执行机器退订操作:
x=0
While read record; do (sleep 2;echo $record)|slcli hardware cancel --immediate $record ; let x++; echo “$x done”; done
7.查看退订生成的工单,确认数量,日期是否都正确:
Slcli ticket list|grep “Canncellation”
如果是虚拟机,步骤同上,只需将slcli命令中的hardware替换成virtual即可。
8.创建预配置的物理机器:
slcli hardware create [options]
Usage: slcli hardware create [OPTIONS]
Order/create a dedicated server.
Options:
-H, --hostname TEXT Host portion of the FQDN [required]
-D, --domain TEXT Domain portion of the FQDN [required]
-s, --size TEXT Hardware size [required]
-o, --os TEXT OS install code [required]
-d, --datacenter TEXT Datacenter shortname [required]
--port-speed INTEGER Port speeds [required]
--billing [hourly|monthly] Billing rate [default: hourly]
-i, --postinstall TEXT Post-install script to download
-k, --key TEXT SSH keys to add to the root user (multiple occurrence permitted)
--no-public Private network only
-e, --extra TEXT Extra options (multiple occurrence permitted)
--test Do not actually create the server
-t, --template PATH A template file that defaults the command-line options
--export PATH Exports options to a template file
--wait INTEGER Wait until the server is finished provisioning for up to X seconds before returning
-h, --help Show this message and exit.
See 'slcli server create-options' for valid options.
slcli server create-options可以查看创建机器所需要输入参数的具体数据和格式,下面列出了部分此命令的输出:
数据中心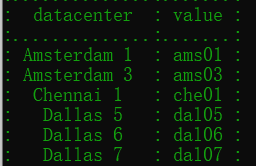
机器size选项参数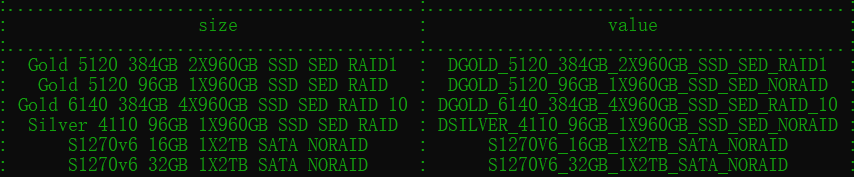
操作系统选项参数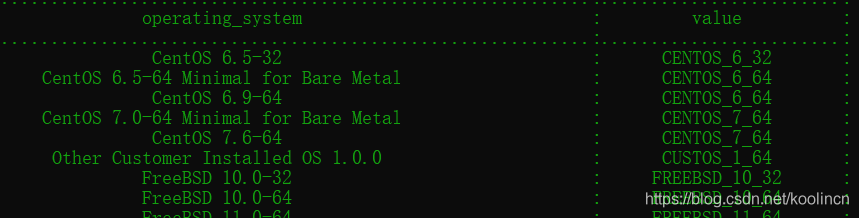
网卡速度选项参数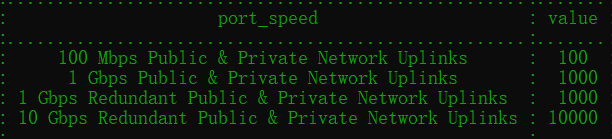
其他(额外ip)
创建物理机命令示例:
C:\Users\TINGZHU>ibmcloud sl hardware create -H zttest -D zhutingsh.com -s DSILVER_4110_96GB_1X960GB_SSD_SED_NORAID -o CENTOS_7_64 -d dal13 -p 100 -t
此次仅对命令执行测试验证,不真正创建机器,如需要真正创建,将命令行末尾的 -t选项删除即可。上面的命令输出如下: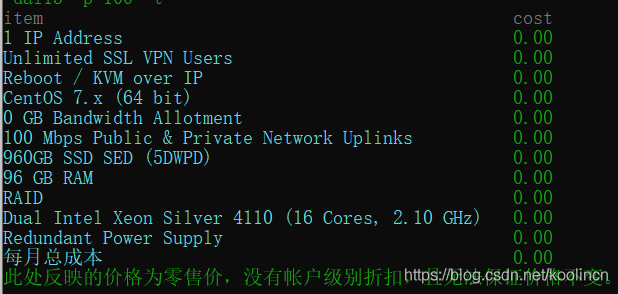
9.创建虚拟服务器实例。
ibmcloud sl vs create [OPTIONS]
命令选项:
-H, --hostname
必需。FQDN 的主机部分。
-D, --domain
必需。FQDN 的域部分。
-c, --cpu
必需。CPU 核心数。
-m, --memory
必需。内存(以兆字节为单位)。
--flavor
Public Virtual Server 类型模板键名。
-d, --datacenter
必需。数据中心短名称。
-o, --os
操作系统安装代码。提示:可以指定 _LATEST。
--image
映像标识。请参阅 ibmcloud sl image list 以获取参考信息。
--billing
计费费率。缺省值为:hourly。选项为:hourly 或 monthly。
--dedicated
创建专用虚拟服务器(专用节点)。
--host-id
要将 Dedicated Virtual Server 供应到的主机标识。
--san
使用 SAN 存储器(而非本地磁盘)。
--test
不创建虚拟服务器。
--export
将选项导出到模板文件。
-i, --postinstall
要下载的安装后脚本。
-k, --key
要添加到 root 用户的 SSH 密钥的标识。可以指定多个标识。
--disk
磁盘大小。可以指定多个大小。
--private
强制虚拟服务器只能访问专用网络。
--like
使用现有虚拟服务器中的配置。
-n, --network
网络端口速度(以 Mbps 为单位)。
-g, --tag
要添加到实例的标记。可以指定多个标记。
-t, --template
对命令行选项使用缺省值的模板文件。
-u, --userdata
用户定义的元数据字符串。
-F, --userfile
从文件中读取用户数据。
--vlan-public
要将虚拟服务器放到其中的公用 VLAN 的标识。
--vlan-private
要将虚拟服务器放到其中的专用 VLAN 的标识。
-S, --public-security-group
要与公共接口关联的安全组标识。可以指定多个标识。
-s, --private-security-group
要与专用接口关联的安全组标识。可以指定多个标识。
--wait
等待虚拟服务器完成供应(最长 X 秒)。
-f, --force
强制操作而不确认。
————————————————
版权声明:本文为CSDN博主「koolincn」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/koolincn/article/details/104492312
eerrrr而对方算法的缝纫工
人工智能显然成了引领新一轮科技革命和产业变革的战略性技术,是国家综合实力与发展核心竞争力的重要体现。国家在人工智能的战略布局让人工智能人才的争夺战日益激烈,人工智能专业学生或许会成为未来最紧缺的人才之一,就业前景十分广阔。
这种交叉点一般是以人工智能专业为主、机械相关专业为辅。智能制造、或者说AI+制造业普遍存在一个痛点,就是行业壁垒高,制造业不懂,AI业进不来。实际上传统制造业,比如焊接、铸造等,工作环境都比较恶劣、劳动强度高,对机器换人的需求比较大。但是这些行业内的企业本身不具备智能制造自动化集成的能力,然后人工智能技术较强的互联网公司都传统机械行业的了解甚少,二者很难结合起来。
大数据和区块链的是两种截然不同的新兴技术,但是它们有着很大的可以结合的空间。
数据分析平台的建设流程基本上可以从数据分析流程来理解,比如数据采集、数据整合、数据加工、数据可视化等等,一般的大数据平台都会包括这些流程,叫做一站式大数据平台。
